
调度:调度框架
调度的目的是要解决在有限资源的情况下如何高效分配资源给消费者的问题。内核中需要调度的地方有很多,比如:对CPU而言,消费CPU的进程需要调度;对IO而言,下发的IO包需要调度;对PMU(perf monitor unit)而言,perf event需要调度,等等。可以说,调度无处不在。本文重点介绍进程的调度框架。对于现今流行的SMP多核架构,本文将从单CPU、任务组、整机SMP三个视角来进行拆解,便于理解其背后的设计原理。
单CPU视角
单CPU视角只看局部独立的一颗CPU是如何高效执行多个任务的。下面这张图展示了单CPU视角涉及的数据结构和一部分执行流程。该流程大致可以分为2部分:
- 在已给定一组任务的场景下,任务怎么存?
- 任务怎么选?
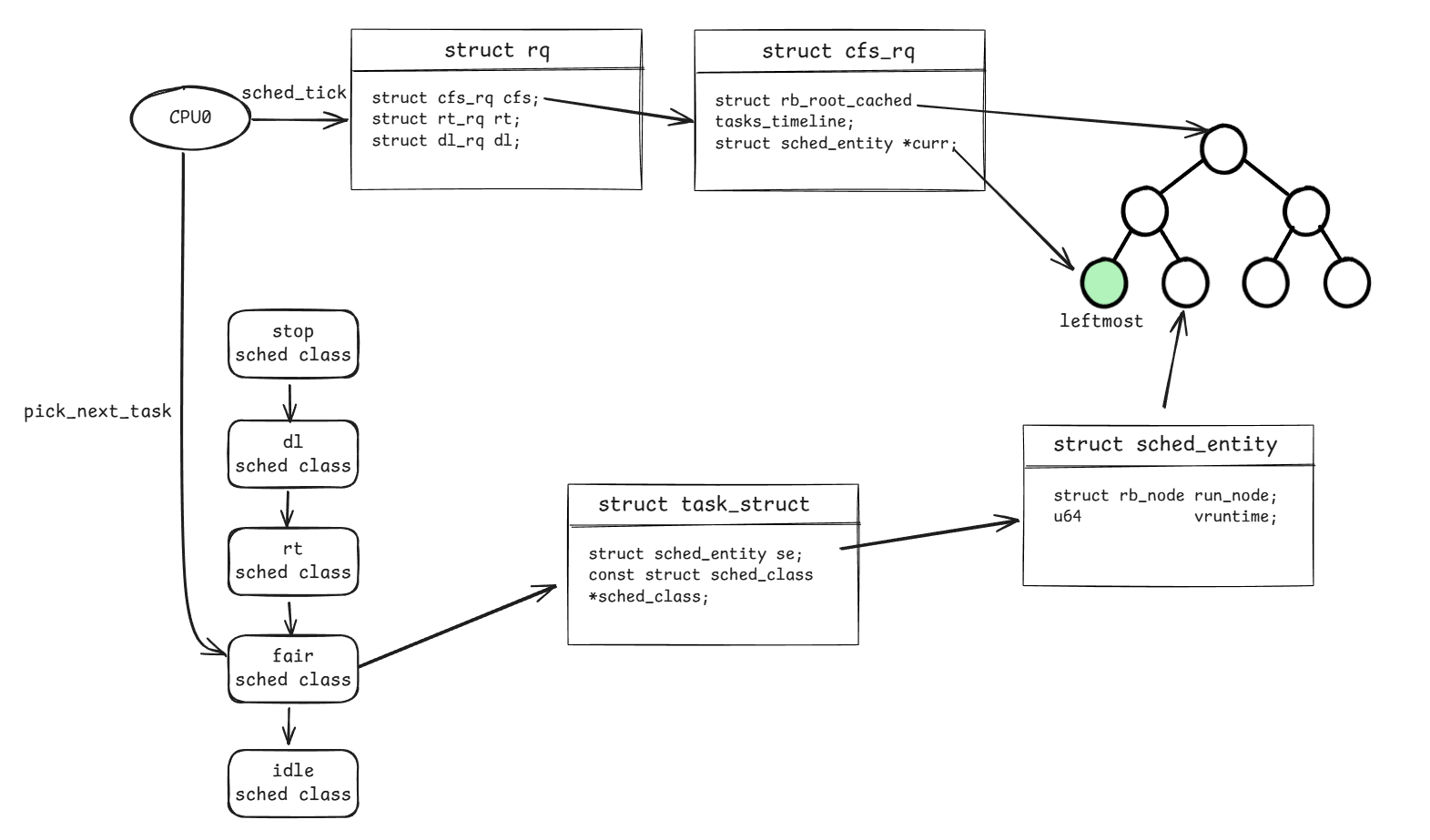
任务怎么存?
内核定义了一个per-cpu变量,为每个cpu都创建了一个runqueue(对应结构体为struct rq),用于存储要被运行的任务。对于单个CPU而言,仅关注自己身上的runqueue即可,有任务在队列里时就处理。
1 | // file: kernel/sched/core.c |
队列的实现有多种,可以是FIFO、FILO的,也可以是最大堆最小堆的等。考虑到任务本身的不同性质(即不同性质的任务其重要程度、对调度的响应延时要求不同,比如内核态线程、用户态线程、关注内核状态的watchdog任务之间的差异),内核给出了多种队列类型:struct cfs_rq、struct rt_rq、struct dl_rq等。
以cfs_rq为例,该队列将一组任务组织成一棵红黑树的形式。其中,树节点并非直接存储task_struct,而是通过struct sched_entity(下文简称se)与task_struct建立联系。提供这层抽象是有好处的,原则上,任何结构体只要包含sched_entity属性,就可以被调度器调度(后面我们将看到一个特殊的sched_entity:group se,作为任务组的抽象进行调度)。
任务怎么选?
红黑树是有序的,具体顺序根据se->vruntime决定,vruntime最小的任务将被放到红黑树的最左边(对应到上述图片中的leftmost),vruntime最小说明该任务被CPU执行的时间最少,最应该被调度,因此将它标记为绿色(内核中将其标记为TIF_NEED_RESCHED)。有了标记后,内核将在合适的时机调用pick_next_task执行。
pick_next_task顾名思义,就是在选取下一个应该被执行的任务。前面提到,由于任务性质的不同,内核定义了多种队列,对于调度类sched class也一样,根据不同的任务性质定义了不同的sched class,并且每个sched class有前后优先级关系。高优先级的调度类优先pick,低优先级后pick。具体pick_next_task的实现如下:
1 | // file: kernel/sched/core.c |
任务执行一段时间后,如何回到队列中等待调度?—— 通过CPU时钟tick来实现。每次时钟tick时,将调用sched_tick来更新当前任务的vruntime,并根据vruntime判断是否有其他任务比当前任务更需要被执行,如果有则与前面流程一样,打上TIF_NEED_RESCHED标记,然后内核将在合适的时机调用pick_next_task执行。
如此反复,就形成了单CPU上调度的基本循环。
任务组视角
任务组视角要考虑的问题是具有关联关系的一组任务应该如何被一起调度。什么样的一组任务会被认为是有关联?最常见的就是cgroup,持有一组任务,通过配置统一管理这些任务的可用时间配额。因此,像这样的一组任务就需要被统一调度。任务组视角已经不再像前面那样只考虑单CPU,而是涉及多CPU,其任务组定义和管理方式如下图所示。该图要解决任务组的两个问题:
- 单CPU上同属于一个任务组的任务子集如何组织?
- 所有CPU上的任务子集如何管理?
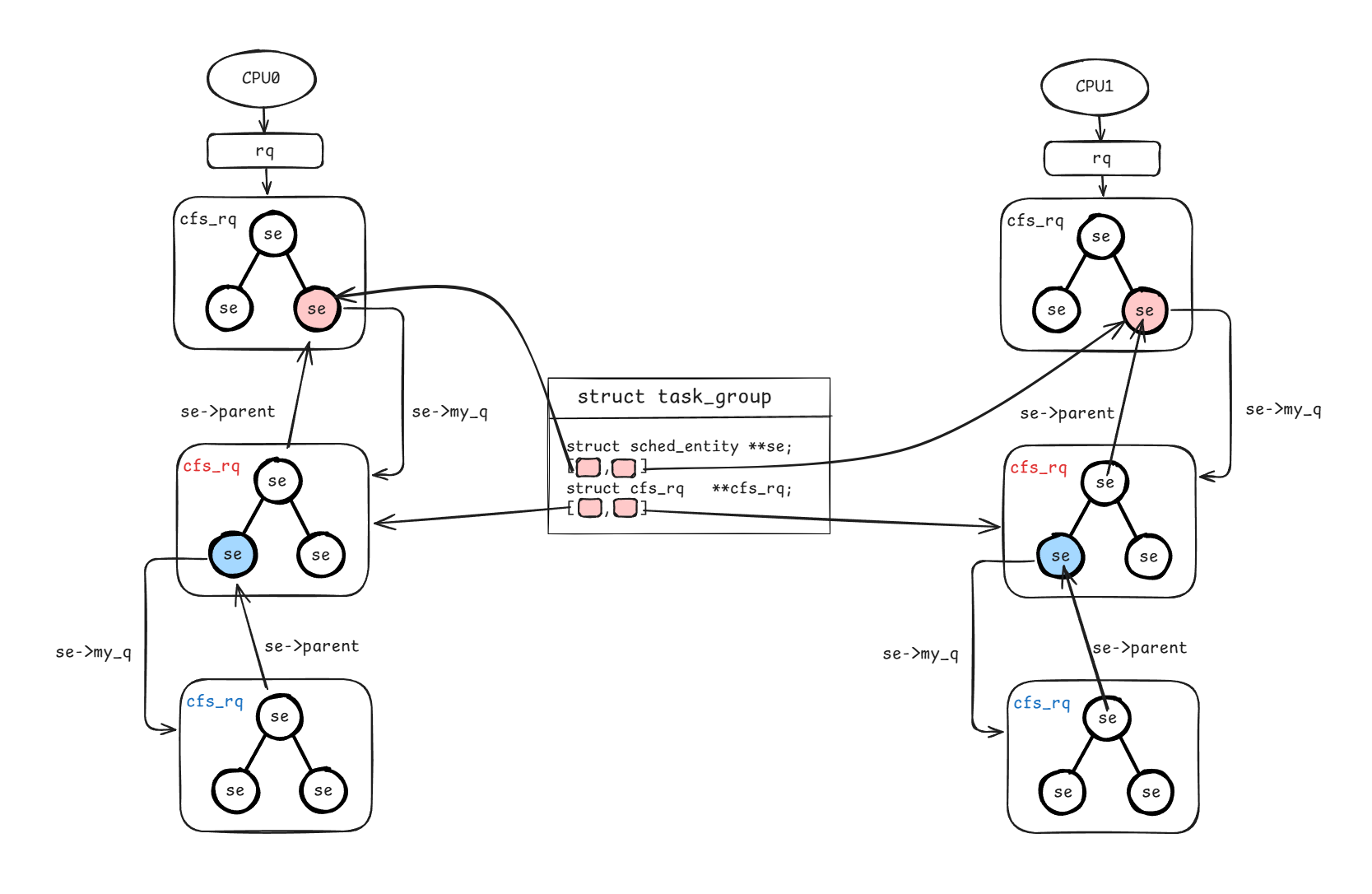
单CPU上同属于一个任务组的任务子集如何组织?
和普通任务一样,单CPU上同一个任务组的任务子集仍然通过cfs_rq组织,不同的是,该cfs_rq不再是全局预定义的每CPU上的队列,而是另外申请的私有队列,任务子集放到该私有队列内独立管理。
那么,单CPU如何知道有这样一个任务子集的存在呢?—— 通过一个特殊的sched_entity:group se(见图中红色标记)。从类型上看,它和普通se并无区别,单CPU视角仍然将其当做一个普通se来处理(比较vruntime、标记、调度等)。而实际上,该se内部会有一个属性se->my_q指向新申请的cfs_rq队列,从而实现任务权重等信息从上到下传递。同样的,group se也需要收集汇总任务子集的vruntime等信息,因此,还需提供一个从下到上的访问路径,该路径通过se->parent实现。
任务组也是支持嵌套的,同样是借助se->my_q和se->parent,如上图蓝色标记所示。
所有CPU上的任务子集如何管理?
我们已经知道单CPU上存在两个特殊定义来管理任务子集:一个是group se,另一个是私有队列cfs_rq。对于任务组特性本身而言,还需要一个全局的视角来管理相同任务组下的所有任务子集,具体通过struct task_group结构体组织:
1 | struct task_group { |
其中se、cfs_rq相当于是两个指针数组,通过该数组即可快速找到所有cpu上的任务子集。
整机SMP视角
整机SMP视角要关注的是如何调度才能使整个系统达成负载均衡。在多核CPU环境,如果不做负载均衡操作,难免会存在这样的情况:有些CPU跑的很满,有些CPU很闲,导致整机吞吐量下降。另外,现今流行的多路服务器、NUMA架构等,也让CPU和CPU之间有了距离和亲和概念,如果在负载均衡时不对亲和关系加以考虑和控制,很有可能造成严重的性能劣化。整机SMP视角根据这些亲和关系将整机的CPU核划分为了多个调度域struct sched d_domain,从而为负载均衡画出了边界。与此同时,引入调度组struct sched_group概念来对CPU集合进行抽象,作为负载均衡时调度的基本单位,不同的调度组之间使用链表关联。下图展示了一个4C8T(4core、8thread)环境的调度域、调度组划分情况:
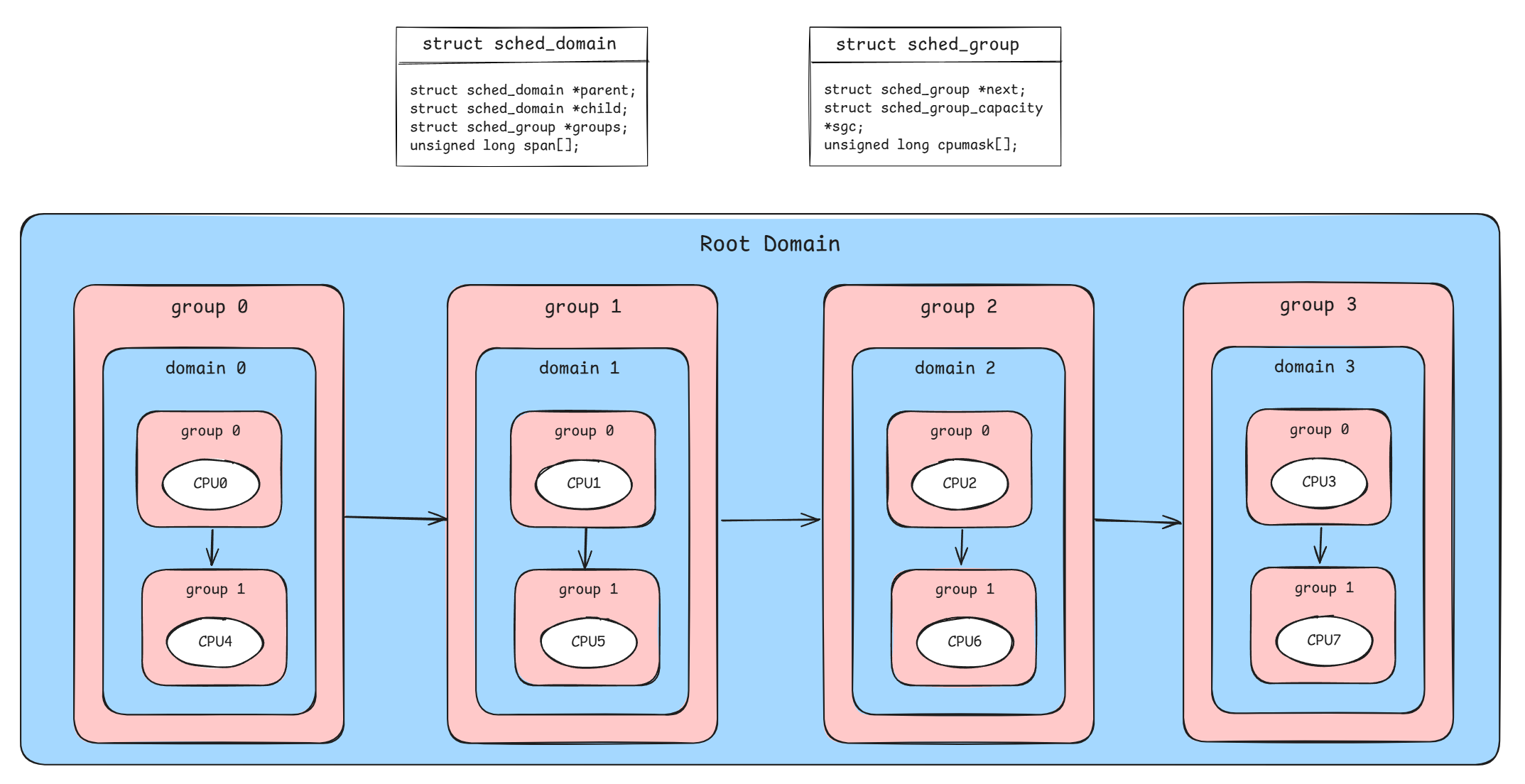
图中,每个CPU都是一个调度组,CPU3是CPU0超线程出来的,二者组成一个调度域(base domain),这是一层。接着,domain 0/1/2/3重新被定义为调度组,这些调度组组合形成一个新的调度域(root domain),这是另一层。发生负载均衡的顺序是从base domain开始,逐层往上回溯:
1 | // file: kernel/sched/sched.h |
很显然,负载均衡是昂贵的操作,因此内核对其做了限频,同时在逐层往上回溯时,如遇到某一层负载已均衡,则提前break,无需继续遍历:
1 | sched_balance_domains |
任务调度始末
前面的三个视角让我们对调度框架有了一定的了解。接下来我们从单个任务的视角切入,具体来看下其调度始末都做了哪些事。
新任务创建加入
新任务创建时,加入到rq队列的流程如下所示。流程上大致可以总结为:
- 先对任务中的se、sched_class做初始化
- 再基于sched_class选核、入队运行
1 | // file: kernel/fork.c |
如果sched_class是公平调度类,则流程中的select_task_rq和enqueue_task将分别对应到select_task_rq_fair和enqueue_task_fair函数。具体可以查看kernel/sched/fair.c文件,本文暂不展开。
老任务被唤醒
任务不总是运行的,可能会因为网络请求尚未到达而阻塞。阻塞状态的任务会出队,当后续网络请求到达时,内核将调用try_to_wake_up使其重新入队运行。具体流程如下:
1 | try_to_wake_up |
队列内任务tick轮转
正如前文所述,由于CPU资源有限,入队后的任务需均分该CPU核的时间片运行。为监控任务的运行时间,必然要依赖一个定时器来周期性观测。该定时器的观测入口为sched_tick,具体调用流程如下:
1 | sched_tick |
触发调度的调用点
假设当前队列内已有任务被标记了,那么在什么时候它会被真正调度起来呢?
- 系统调用返回用户态时
- 中断完成返回内核/用户态时
以早期的x86内核为例(具体应该是5.8以前?之后这块内核代码有较大改动,见75da04f7f3c (x86/entry: Remove the apic/BUILD interrupt leftovers))
1、系统调用返回用户态时触发调度的路径:
1 | // file: arch/x86/entry/entry_64.S |
2、中断完成返回内核/用户态时触发调度的路径:
1 | // file: arch/x86/entry/entry_64.S |
可以看到,最终调度执行都会走到__schedule()函数。函数实现如下所示。该函数将通过调度类pick下一个任务,并通过context_switch将prev任务从当前cpu卸载,并将next任务加载到当前cpu上,此部分动作包括保存寄存器、切换页表等体系结构的内容,较为复杂,这里暂不展开。
1 | __schedule |



