PSI全称为Pressure Stall Information,是一种衡量系统负载压力的方法。PSI所要测量的对象包括cpu、memory和io三部分(在近期的内核6.12+中新加入了irqtime),其测量的粒度是cgroup级别的,当cgroup层级为1时,则测量的是整个系统的负载。对于系统的负载,PSI将压力信息输出在/proc/pressure/{cpu,memory,io},而对于cgroup的负载,压力信息则输出到/sys/fs/cgroup/xxx/{cpu,memory,io}.pressure,具体输出格式为:
1 2 3 root@ubuntu-server:~ some avg10=0.09 avg60=0.18 avg300=0.80 total=345815613 full avg10=0.00 avg60=0.00 avg300=0.00 total=0
和前面介绍的loadavg 一样,PSI输出的压力信息同样分为了3个时间段:10、60、300s;但和loadavg不同的是,PSI还将压力分为了some、full两种类别(具体差异将在下文介绍)。故PSI所观测的压力信息比loadavg更具体,尤其是在容器场景。
本文将着重介绍PSI观测指标的含义以及其观测原理,从而加深对PSI机制的理解。
观测指标 已知PSI将负载压力从观测对象(cpu/memory/io)、观测粒度(system/cgroup)以及观测类别(some/full)三个维度做了细分,每一种观测对象、粒度,其观测的信息和手法基本一致,唯一需要明确的是观测类别中some和full的差异。
一个cgroup中有多个任务,任务之间有概率因争夺有限的cpu、memory、io资源而导致相互阻塞,具体阻塞等待的程度如何,通过some、full来表征。some、full都是针对单个CPU而言 ,其中:
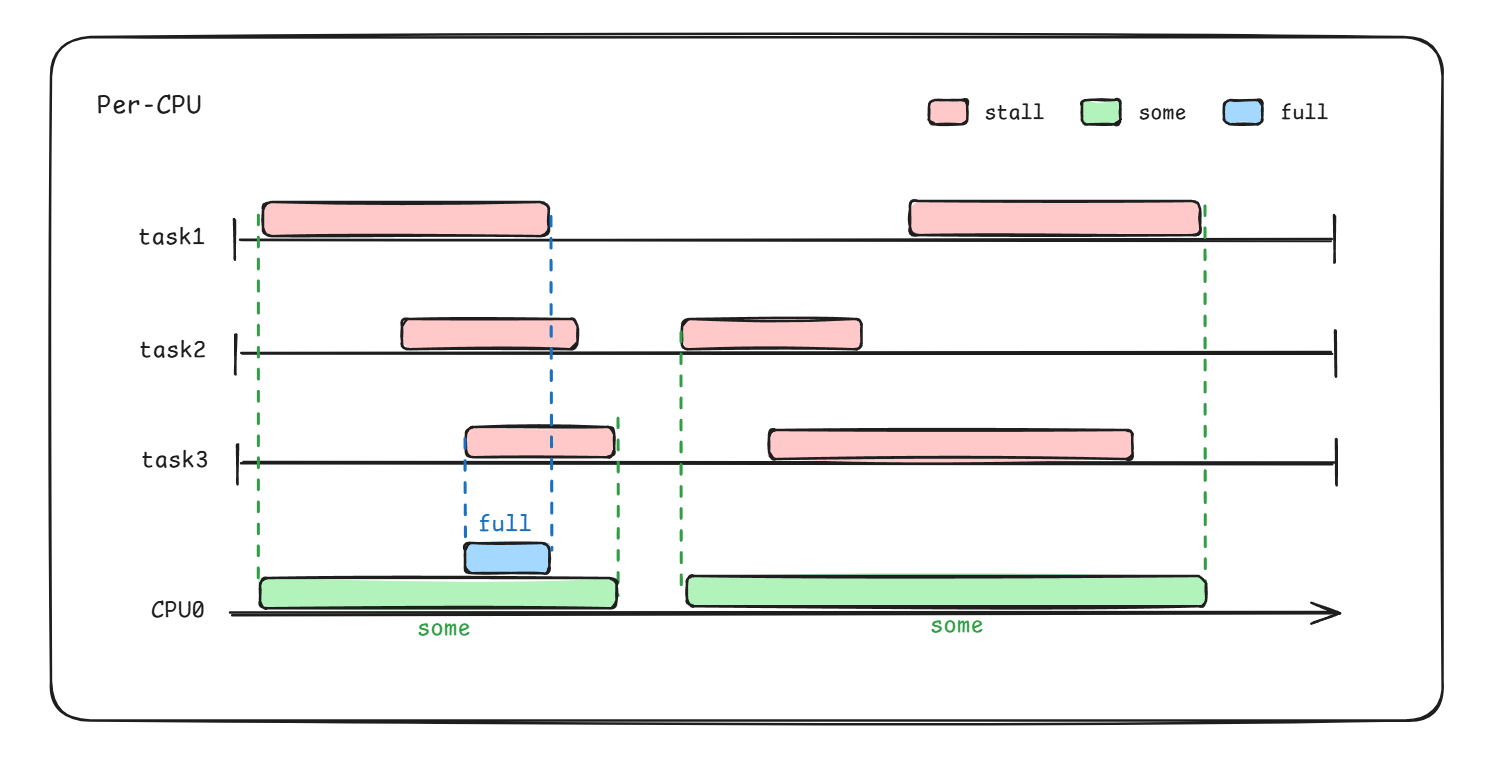
some表示任意时刻某CPU上相同cgroup中的一些任务发生了阻塞;
而full则表示任意时刻某CPU上相同cgroup中的所有任务都发生了阻塞
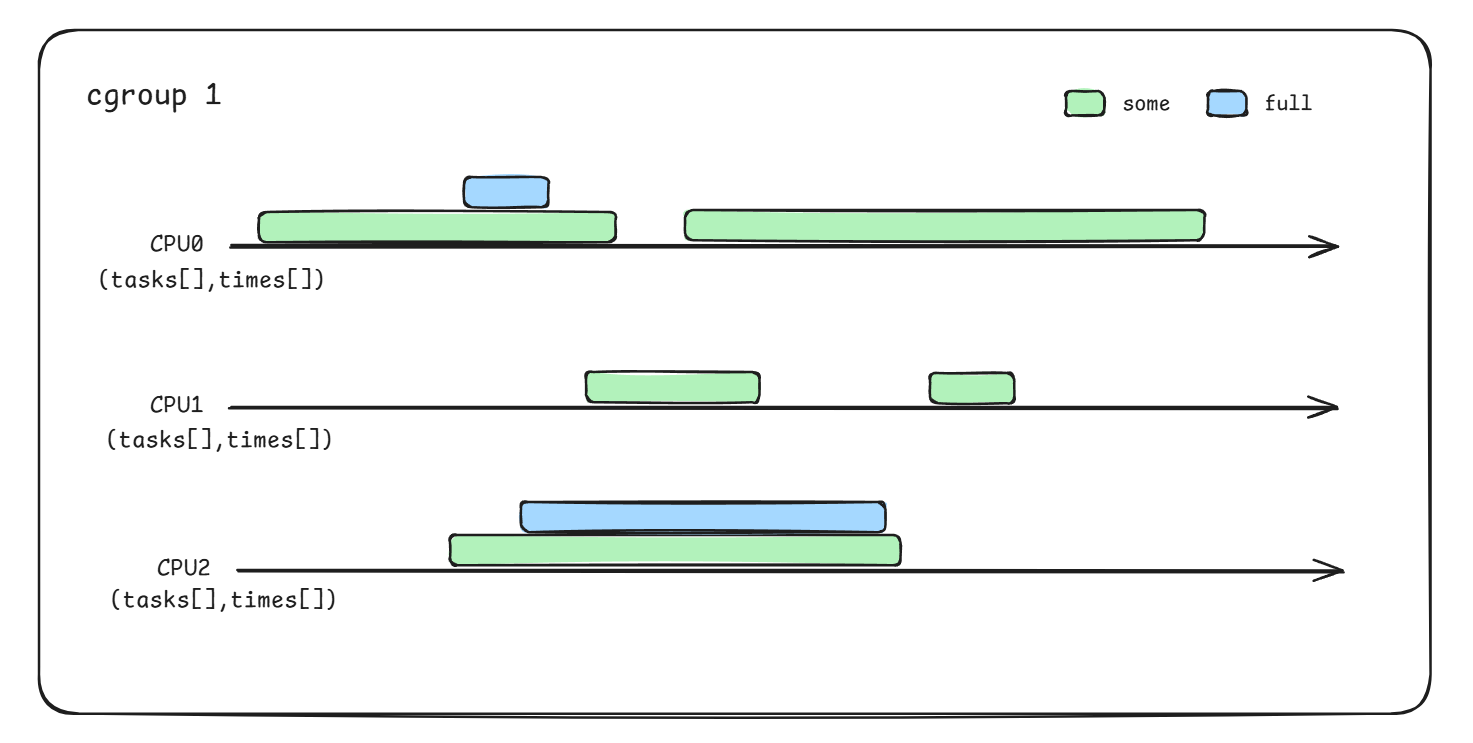
具体some、full区间如下图绿/蓝色块所示(假设task1/2/3均属于同一cgroup):
PSI正是通过识别这样的状态,并统计其阻塞时长和相对于整个cgroup运行时长的占比,从而计算出cgroup的负载压力。
观测原理 那么some、full的具体值是如何计算的呢?可以通过处于stall状态的任务数来看。
some/full状态识别 以前面示意图为例,已知总任务数为3,对于some区间,发生stall的任务数总是小于等于3,但大于0;对于full区间,发生stall的任务数总是等于3。如果任意时刻处于stall的任务数能够统计出来,那么根据该数量即可区分some、full。PSI代码实现如下所示:
1 2 3 4 5 6 7 8 9 10 11 static u32 test_states (unsigned int *tasks, u32 state_mask) { ... if (tasks[NR_MEMSTALL]) { state_mask |= BIT(PSI_MEM_SOME); if (tasks[NR_RUNNING] == tasks[NR_MEMSTALL_RUNNING]) state_mask |= BIT(PSI_MEM_FULL); } ... }
接下来解决2个问题:
tasks数量如何统计?
已知当前的some/full状态了,如何用于计算负载?
tasks数量统计 首先准备一个per-cpu类型的tasks数组,因为要统计多种类别的tasks,故对该数组的每个元素位置进行定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 enum psi_task_count { NR_IOWAIT, NR_MEMSTALL, NR_RUNNING, NR_MEMSTALL_RUNNING, NR_PSI_TASK_COUNTS = 4 , }; struct psi_group_cpu { unsigned int tasks[NR_PSI_TASK_COUNTS]; }
接着定义4个任务状态位,通过其追踪任务状态:
1 2 3 4 5 6 7 8 9 #define TSK_IOWAIT (1 << NR_IOWAIT) #define TSK_MEMSTALL (1 << NR_MEMSTALL) #define TSK_RUNNING (1 << NR_RUNNING) #define TSK_MEMSTALL_RUNNING (1 << NR_MEMSTALL_RUNNING) #define TSK_ONCPU (1 << NR_PSI_TASK_COUNTS)
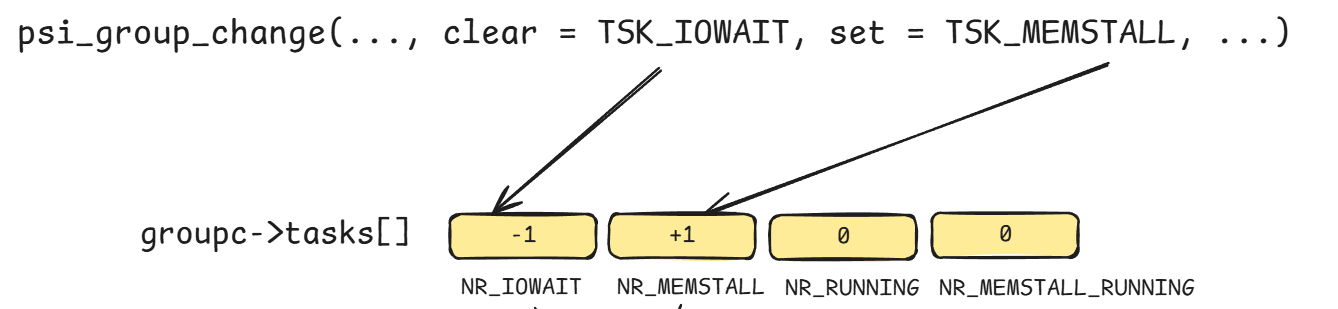
有了这些状态,我们可以很容易对tasks数组对应的位置计数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 static void psi_group_change (struct psi_group *group, int cpu, unsigned int clear, unsigned int set , bool wake_clock) { ... for (t = 0 , m = clear; m; m &= ~(1 << t), t++) { if (!(m & (1 << t))) continue ; if (groupc->tasks[t]) { groupc->tasks[t]--; } } for (t = 0 ; set ; set &= ~(1 << t), t++) if (set & (1 << t)) groupc->tasks[t]++; }
具体效果如下所示:
剩下要解决的就是为psi_group_change寻找合适的位置埋点。以cpu为例,其埋点位置位于任务enqueue、dequeue的时候:kernel/sched/core.c
1 2 3 4 5 6 7 8 9 10 11 12 enqueue_task psi_enqueue set = TSK_RUNNING; psi_task_change(p, clear, set ); psi_group_change(..., clear, set , ...); dequeue_task psi_dequeue psi_task_change (p, p->psi_flags, 0 ) ; psi_group_change(..., clear, set , ...);
memory和io的埋点位置虽和cpu有差异,但大体原理一致,这里不具体展开。
some/full状态使用 了解完some/full状态识别和tasks统计后,剩下就是计算负载了。
负载计算依赖时间统计,为此,和tasks数组类似,PSI也声明了一个times数组,用来容纳some/full的累积时间信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 enum psi_states { PSI_IO_SOME, PSI_IO_FULL, PSI_MEM_SOME, PSI_MEM_FULL, PSI_CPU_SOME, PSI_CPU_FULL, PSI_NONIDLE, NR_PSI_STATES, }; struct psi_group_cpu { u32 state_mask; u32 times[NR_PSI_STATES]; }
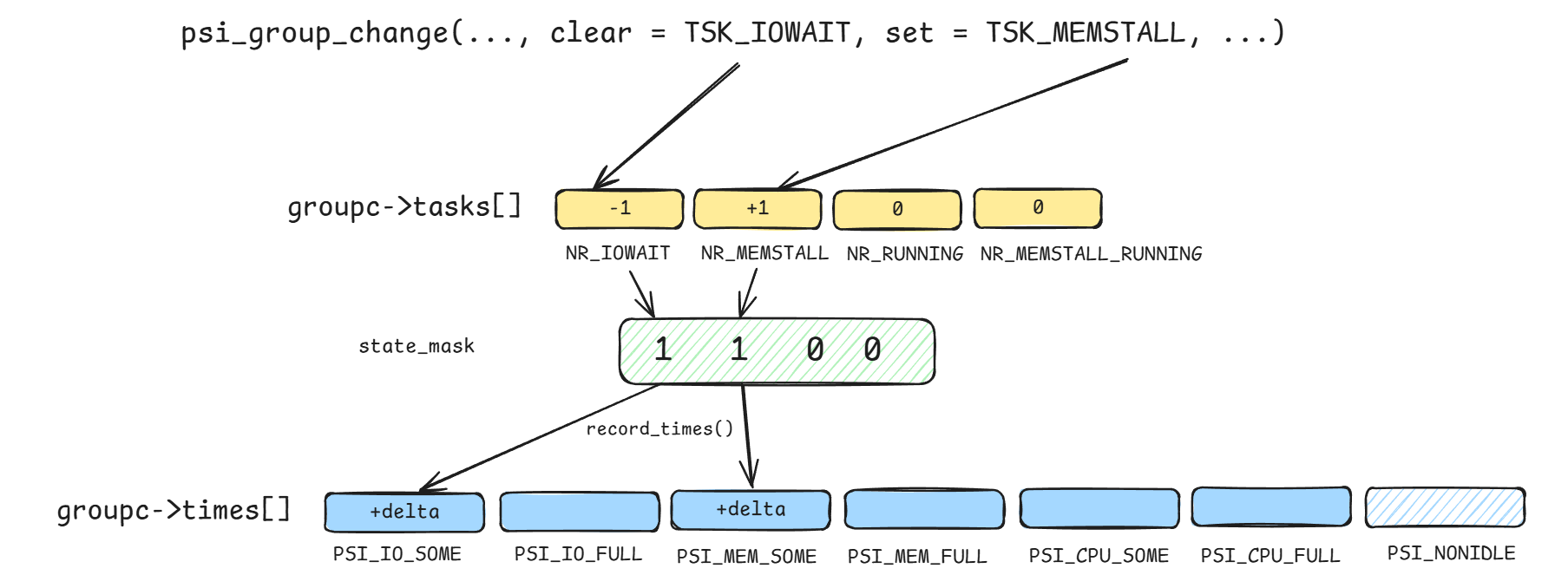
有了times数组后,就可以通过前面识别的some/full状态来计数了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 static void record_times (struct psi_group_cpu *groupc, u64 now) { u32 delta; delta = now - groupc->state_start; groupc->state_start = now; if (groupc->state_mask & (1 << PSI_IO_SOME)) { groupc->times[PSI_IO_SOME] += delta; if (groupc->state_mask & (1 << PSI_IO_FULL)) groupc->times[PSI_IO_FULL] += delta; } ... }
所以tasks和times的总体关系可以描绘如下:
times数组是时间累积,还不是最终输出的10、60、300s的负载压力值,那它们之间是什么时候做的转换,怎么转换?PSI通过一个delay work(延迟任务)来做,定时将times的累计值“fold”为负载。
delay work初始化:
1 2 3 4 5 6 7 static void psi_avgs_work (struct work_struct *work) ;static void group_init (struct psi_group *group) { INIT_DELAYED_WORK(&group->avgs_work, psi_avgs_work); }
delay work触发:
1 2 3 psi_group_change schedule_delayed_work (&group->avgs_work, PSI_FREQ) ;
delay work函数实现包含两个步骤:
先搜集各cpu的times值,通过nonidle时间来加权计算平均值,存入total
根据total值的增量,计算最终负载
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 psi_avgs_work collect_percpu_times for_each_possible_cpu (cpu) { u32 times[NR_PSI_STATES]; u32 nonidle; u32 cpu_changed_states; get_recent_times(group, cpu, aggregator, times, &cpu_changed_states); changed_states |= cpu_changed_states; nonidle = nsecs_to_jiffies(times[PSI_NONIDLE]); nonidle_total += nonidle; for (s = 0 ; s < PSI_NONIDLE; s++) deltas[s] += (u64)times[s] * nonidle; } for (s = 0 ; s < NR_PSI_STATES - 1 ; s++) group->total[aggregator][s] += div_u64(deltas[s], max(nonidle_total, 1UL )); update_averages for (s = 0 ; s < NR_PSI_STATES - 1 ; s++) { u32 sample = group->total[PSI_AVGS][s] - group->avg_total[s]; group->avg_total[s] += sample; calc_avgs(group->avg[s], missed_periods, sample, period); }
步骤1中,nonidle定义为只要存在cpu/memory/io阻塞的task,那就认为是nonidle状态。用代码实现的话就是:
1 2 3 4 5 6 static u32 test_states (unsigned int *tasks, u32 state_mask) { ... if (tasks[NR_IOWAIT] || tasks[NR_MEMSTALL] || tasks[NR_RUNNING]) state_mask |= BIT(PSI_NONIDLE); }
步骤2中,如果打开calc_avgs,将会看到熟悉的calc_load函数,该函数来自loadavg。也就是说,PSI最终计算10/60/300s三个时间段负载的方法仍然是沿用了loadavg那一套。